Глава I
АВТОМАТИЗИРОВАННЫЕ СИСТЕМЫ ИНЖЕНЕРИИ ЗНАНИЙ
 1.1 Задача формирования баз знаний
1.1 Задача формирования баз знаний
1.2 Способы представления знаний
Продукционные системы • Семантические сети •
Фреймы • Логические исчисления •
Комбинированные способы представления знаний •
Модели проблемных областей
1.3 Инструментальные экспертные системы
1.4 Принципы организации опроса эксперта и системы приобретения знаний
Простое и структурированное интервью • Протокольный анализ •
Метод декомпозиции цели • Методы сопоставления •
Методы заочной консультации
1.5 Принципы построения автоматизированных систем инженерии знаний
1.6 Специальные обозначения
| |
Веб-версия диссертации размещена автором на www.park.glossary.ru.
Копии веб-версии на иных сайтах заведомо получены и размещены с нарушением
авторских прав, без согласия и без отвественности автора. |
Проблема формирования баз знаний является сложной и многогранной. Если
ограничить рассмотрение этой проблемы задачей извлечения личных знаний эксперта,
то можно сформулировать основные требования и принципы построения программных
систем, автоматизирующих процесс формирования баз знаний. Системы такого рода
именуются автоматизированными системами инженерии знаний.
В настоящей главе - по умолчанию - используется терминология
искусственного интеллекта в том смысле, как она определена в [44].
1.1 Задача формирования баз знаний
При всей претенциозности своего названия, инженерия знаний является
дисциплиной сугубо прозаической, в ее задачу входит разработка практически
полезных программ для слабо "математизированных" областей человеческой
деятельности. Главным аргументом в пользу плодотворности такого подхода
является факт существования в реальной жизни института экспертов - классных
профессионалов, способных решать плохо формализуемые задачи из той или иной
проблемной области.
С точки зрения инженерии знаний, в любой прикладной программе (по-крайней
мере теоретически) можно выделить компоненту, содержащую знания о проблемной
области. Именно эта компонента, именуемая базой знаний, определяет практическую
ценность программы. Построение базы знаний требует специальных изысканий в
проблемной области, в то время как остальные блоки программы находятся
полностью в ведении программиста.
Для плохо формализованных проблемных областей построить исчерпывающую базу
знаний не представляется возможным. Как показывает опыт, последнее утверждение
справедливо даже для относительно простых задач. В связи с этим базу знаний
имеет смысл выделить в самостоятельный элемент структуры, с тем, чтобы ее
модификации не влияли на остальные блоки программы. Причем выразительные
средства, предназначенные для описания баз знаний, - способы представления
знаний - должны быть достаточно просты и понятны.
Понимание ключевой роли базы знаний, а также особый подход
к ее реализации, приводят к необходимости разрешения проблем
наполнения, хранения и использования баз знаний. Круг перечисленных
задач и методов их решения составляет предмет исследования
инженерии знаний как особого раздела искусственного интеллекта.
При правильной постановке дела разработкой базы знаний
занимается специально обученный когнитолог (инженер по знаниям).
В его обязанности входит сопровождение всех этапов разработки
программного продукта [21],
начиная от (1) исследования проблемной области,
последующих (2) наполнения и отладки базы знаний,
вплоть до (3) заключительного тестирования.
Методы формирования баз знаний существенно различаются в
зависимости от используемого источника знаний. В инженерии
знаний рассматриваются следующие способы получения формализованных знаний:
— анализ специальных текстов;
— восстановление закономерностей из эмпирических данных;
— извлечение личных знаний эксперта(ов).
В дальнейшем мы будем рассматривать задачу формирования баз
знаний в контексте извлечения личных знаний эксперта.
Первоначально считалось, что после того как когнитолог
определится со способом представления знаний, всю дальнейшую
работу по наполнению и отладке базы знаний выполняет
непосредственно эксперт. Такая технология построения баз знаний
называется прямым извлечением. После неудачных попыток
реализовать прямое извлечение знаний в полном объеме, выяснилась
достаточно сложная картина взаимоотношений между экспертом и
базой знаний, отражающей его опыт. Оказывается, что личные
знания и профессиональные навыки эксперта по ряду причин
противодействуют реализации технологии прямого извлечения [5].
Во-первых, знания эксперта не имеют модульной структуры. Дело в том, что в
результате многократного повторения однотипных рассуждений, схемы вывода
представляются эксперту в едином, "скомпилированном" виде.
Во-вторых, наиболее существенные знания эксперта носят невербализованный
характер, поскольку они приобретались непосредственно из практики, минуя какое
бы то ни было использование языка. Другими словами, самые важные знания
эксперта существуют в форме образов или ассоциаций и не имеют даже простой
словесной формулировки, не говоря уже о придании им специального
структурированного вида.
В-третьих, для того, чтобы правильно излагать знания, эксперт должен уметь
фиксировать ход своих рассуждений. Однако рассчитывать на самонаблюдения
эксперта особенно не приходится, поскольку такого рода деятельность человеку
просто не свойственна. Конечно, эксперт способен объяснить полученное им
решение, однако способ объяснения сильно отличается от истинного хода
рассуждений. Кроме того, все логические закономерности, которыми оперирует
эксперт в своих объяснениях, справедливы только в контексте данного примера.
Весь этот комплекс причин низводит прямое извлечение до
уровня одного - быть может не самого лучшего - метода наполнения
баз знаний. Более плодотворными оказываются косвенные методы
извлечения, когда эксперт по просьбе когнитолога выполняет
некоторые задания, не выходящие за пределы его профессиональной
компетенции. В этом случае когнитолог, наблюдая за действиями
эксперта, имеет возможность реконструировать схему его
рассуждений и отдельные фрагменты знаний. В дальнейшем
выявленные знания дорабатываются в процессе отладки.
Формирование баз знаний - процесс весьма длительный. Между
тем, эксперт обычно сильно загружен основной работой, и поэтому
он может уделить когнитологу не очень много внимания. Ситуация
дополнительно осложняется монотонным характером процесса. Если
когнитолог не предпримет специальные меры, то в конечном итоге
эксперт может потерять интерес к созданию базы знаний, что
негативно скажется на судьбе всего проекта.
По принципиальным соображениям процесс формирования баз знаний не поддается
полной автоматизации. Вместе с тем специфика задачи и ее трудоемкость
объективно инициируют разработку инструментальных систем, поддерживающих
частные методики формирования баз знаний.
В классе инструментальных систем, поддерживающих технологию разработки баз
знаний, выделяются автоматизированные системы инженерии знаний (АСИЗ)
непосредственно ориентированные на извлечение экспертных знаний. Определяющими
особенностями АСИЗ являются:
— ориентация на извлечение знаний посредством
автоматизированного опроса эксперта под общим контролем когнитолога;
— информационная и инструментальная поддержка деятельности
когнитолога по анализу протоколов опроса и формированию баз знаний.
В настоящее время автоматизированные системы инженерии знаний представляют
собой уникальные программные продукты, обобщающие конкретный опыт того или
иного когнитолога. В связи с этим назрела необходимость в разработке общей
концепции АСИЗ, которая позволит:
(1) стандартизовать подходы к реализации АСИЗ, что совершенно
необходимо для их практического применения,
(2) развивать проблематику АСИЗ как самостоятельное научное направление.
Систематическое изложение проблематики АСИЗ предполагает:
- описание формальных структур для представления знаний
(полученных с помощью АСИЗ);
- уточнение соотношения между АСИЗ и общим классом систем
инженерии знаний, которые традиционно подразделяются на:
- инструментальные экспертные системы, предназначенные главным образом
для манипулирования формальными структурами знаний;
- системы приобретения знаний, предназначенные для
поддержки деятельности когнитолога;
- анализ методов ведения диалога с экспертом, продуктивных
с точки зрения извлечения знаний и допускающих реализацию в АСИЗ.
1.2 Способы представления знаний
В настоящее время известны четыре основных модели знаний, из которых
можно конструировать "гибридные" способы представления знаний.
1.2.1 Продукционные системы
Продукционная модель знаний [29] рассматривается в связи с
абстрактной системой, состоящей из информационной структуры,
базы знаний и интерпретатора [58].
Информационная структура представляет собой объект (в смысле
объектно-ориентированного программирования), который включает в себя:
— базу фактов, предназначенную для хранения записей;
— набор сопоставителей [26], позволяющих проверять текущее
состояние базы фактов;
— операции по преобразованию базы фактов; в частности,
обязательно определена операция включения новой записи.
Не ограничивая общности, можно считать, что при инициализации информационной
структуры в базу фактов заносится некоторое количество записей.
База знаний состоит из правил (продукций) вида
ЕСЛИ <Условие>, ТО <Действие>, где
<Условие> — конкретный вызов некоторого сопоставителя;
<Действие> — конкретный вызов некоторой операции преобразования
базы фактов.
В терминологии продукционных систем <Условие> иногда называется левой частью
правила или условием применимости, а <Действие> - правой частью правила.
Интерпретатор реализует алгоритм вывода, который в общем случае позволяет
последовательно выполнить правые части некоторых правил с истинными на текущий
момент условиями применимости. В своей работе алгоритм вывода использует
специальную процедуру разрешения конфликтов. Перед вызовом этой процедуры
интерпретатор формирует так называемое конфликтное множество правил, а в
обязанности процедуры входит выбор ровно одного правила из этого множества.
В известном алгоритме прямого вывода конфликтное множество образуют правила
с истинными на данный момент условиями применимости, а после разрешения
конфликта интерпретатор выполняет действие из правой части выбранного правила.
Циклически повторяя эту последовательность, алгоритм прямого вывода шаг за
шагом модифицирует базу фактов.
Продукционная система реализует способ представления знаний, если
зафиксированы: все компоненты информационной структуры, алгоритм вывода и
(возможно) процедура разрешения конфликтов. Простейший способ представления
знаний на базе продукционной модели предполагает следующую организацию
информационной структуры:
— база фактов есть неупорядоченное множество неделимых
записей; в данном случае неделимость фактов означает, что
их можно сравнивать только на равенство;
— единственный сопоставитель реализует проверку вложенности
заданного множества фактов в текущую базу фактов;
— единственное действие реализует запись заданного множества
фактов в базу фактов.
Сделанные предположения позволяют упростить нотацию правил,
исключив из них явное указание сопоставителя и операции. В
результате такого преобразования правила приобретают вид:
ЕСЛИ Ф1 И ... И Фn, ТО F1 И ... И Fm,
где Ф1, ... Ф1, F1, ..., F1 -
факты. Если на местах фактов располагаются их названия,
то правила становятся вполне понятными без дополнительных разъяснений.
Пример.
ЕСЛИ "отдых: летом" И "человек: активный",
ТО "следует ехать: в горы"
(n = 2, m = 1) 
Дополнительно считается, что некоторые правила отмечены в базе знаний как
заключительные, и их использование зависит от конкретного алгоритма логического
вывода. Так, алгоритм прямого вывода заканчивает свою работу после выполнения
действия из заключительного правила. Если же в базе знаний отсутствуют такие
правила, то алгоритм построит все следствия из первоначально заданного
множества фактов.
В практических приложениях для баз знаний, содержащих
упрощенные правила, часто используется алгоритм обратного
вывода. Свою работу этот алгоритм начинает с того, что выбирает
факт из правой части некоторого заключительного правила и
пытается построить его вывод. Если попытка оказалась неудачной,
то по тому же принципу выбирается другой факт и т.д. Процедура
проверки заданного факта на выводимость является рекурсивной:
| факт |
либо непосредственно содержится в базе фактов, |
|
либо его можно вывести с помощью некоторого правила из базы знаний. |
В последнем случае конфликтное множество образуют все правила,
содержащие в правой части заданный факт, а после разрешения
конфликта интерпретатор рекурсивно проверяет выводимость каждого
факта из левой части выбранного правила. По сути дела, обратный
вывод реализует поиск в глубину с возвратами.
Несмотря на свою простоту, описанная разновидность
продукционных систем позволяет успешно разрабатывать экспертные
системы для задач распознавания и классификации. Более того,
подход является настолько популярным, что некоторые авторы
просто опускают все оговорки насчет его особого происхождения.
Замечание 1.1.
В упрощенной модели продукционных систем не имеет смысла рассматривать
несколько выводов одного и того же факта. Однако ситуация меняется, когда с
каждым фактом связывается некоторый коэффициент уверенности, позволяющий
моделировать правдоподобные рассуждения. В данном случае нас интересует задача
совмещения коэффициентов уверенности.
Пусть некоторый факт f имеет коэффициент уверенности a, и пусть в результате
некоторого вывода этот же факт получил коэффициент уверенности b. Задача
совмещения состоит в том, чтобы построить для факта f новый коэффициент
уверенности c = c(a,b).
Самый известный метод решения задачи совмещения предложен в экспертной
системе MYCIN. Здесь считается, что все коэффициенты уверенности принадлежат
отрезку [-1,+1], причем -1 соответствует полному отрицанию факта, а +1 означает
его полное подтверждение. Для вычисления нового коэффициента уверенности
используется формула Шортлиффа [12]
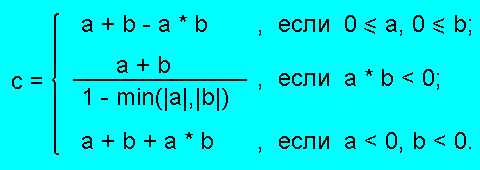
Покажем, что предложенный в системе MYCIN метод совмещения
коэффициентов уверенности является тривиальным.
Рассмотрим функциональное уравнение
y(x + u) = y(x) + y(u) - y(x) * y(u) при y(0) = 0.
Формальными преобразованиями это уравнение сводится к
параметрическому дифференциальному уравнению
y' = p * (1 - y) при y(0) = 0,
где параметр p есть значение y'(0). Единственным решением
дифференциального уравнения является функция
y(x) = 1 - exp(-px).
Зафиксируем некоторое положительное значение параметра p и определим функцию
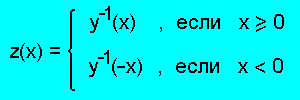
С точки зрения нестандартного анализа [45] функция z есть
отображение отрезка [-1,+1] на гипердействительную прямую,
причем значению +1 (-1) соответствуют положительные
(отрицательные) бесконечно большие числа. Нетрудно проверить,
что для любой пары чисел <a,b> такой, что
a ∈ [-1,+1], b ∈ [-1,+1] и <-1,+1> ≠ <a,b> ≠ <+1,-1>
имеет место равенство z(c) = z(a) + z(b), где c = c(a,b) -
коэффициент уверенности, вычисленный по формуле Шортлиффа.
Итак, система правдоподобных рассуждений, основанная на
формуле Шортлиффа, допускает эквивалентное преобразование (с
помощью функции z(x)) к такому виду, когда совмещение
коэффициентов уверенности выполняется простым сложением чисел.
(Конец замечания 1.1.)
Не останавливаясь подробно, отметим, что для реализации
процедур разрешения конфликтов наработано большое количество
эвристик типа "При прочих равных предпочтение следует отдать
правилу с самым сложным условием применимости" [18]. В общем
виде задача разрешения конфликтов рассмотрена в [15].
1.2.2 Семантические сети
Семантическая сеть - как способ представления знаний - предназначена для
отображения понятийной структуры проблемной области. С формальной точки зрения
семантическая сеть представляет собой ориентированный граф с помеченными
вершинами и ребрами. Вершины графа соответствуют информационным единицам,
в качестве которых могут выступать конкретные или абстрактные понятия, а также
семантические сети более низкого уровня. С помощью дуг в семантической сети
представляются отношения между информационными единицами. В общем случае
механизм вывода в семантической сети сводится к поиску подграфа,
удовлетворяющего заданному образцу (соспоставителю).
Представление знаний посредством семантической сети
предполагает решение вопроса о выборе базового множества понятий
и отношений. Кроме того, когнитологу необходимо рассмотреть специфический
вопрос о представлении выбранных отношений в семантической сети.
Несмотря на то, что базовые отношения определяются
спецификой проблемной области, тем не менее существует набор
универсальных отношений, присутствующих практически во всех
задачах. Речь идет об отношениях типа "элемент - множество"
(ЭЛ), "подмножество - множество" (ПМ), "часть - целое" и т.д. Именно эти
отношения позволяют структурировать знания о проблемной области.
Самым изученным классом семантических сетей является класс
сетей с бинарными отношениями. С помощью этого способа
представления знаний можно отобразить все взаимосвязи между
парами понятий проблемной области. В частности, в такой сети
наглядно представимы знания о свойствах (см. 1.2.6). Сети с
бинарными отношениями весьма популярны для представления знаний
о задачах распознавания и классификации.
Замечание 1.2.
В специальной литературе встречаются описания
"нетрадиционных" способов представления знаний, которые не
используют терминологию семантических сетей, однако на самом
деле реализуют их некоторую разновидность, конкретизированную с
точки зрения компактного представления сети в памяти ЭВМ. В
такого рода случаях имеет смысл различать семантическую сеть как
способ представления знаний и логическое представление самой
семантической сети.
Переход от бинарных отношений к представлению отношений
более высокой арности приводит к существенному усложнению сети
за счет появления новых классов абстрактных понятий и
вспомогательных (ролевых) отношений. Для того, чтобы представить
в сети набор из трех и более понятий, находящихся в заданном
отношении, необходимо выполнить следующие операции:
(1) создать новую вершину, соответствующую исходному набору понятий;
(2) построенную вершину соединить ребрами с теми понятиями, которые входят в исходный набор;
(3) построенные ребра пометить именами бинарных отношений,
отображающими роли понятий в заданном отношении.
Пример.
Рассмотрим вопрос о представлении в виде семантической сети
обычной таблицы умножения. Каждое умножение содержит по три
числа, выполняющих соответственно роли первого сомножителя,
второго сомножителя и результата. Элементарный подсчет
показывает, что сеть должна содержать:
| 41 |
вершину для обозначения чисел, встречающихся в таблице умножения; |
| 100 |
вершин для обозначения конкретных умножений; |
| 2 |
вершины для обозначения множеств чисел и умножений; |
| 141 |
ребро, отображающее отношение ЭЛ; |
| 100 |
ребер, характеризующих некоторые числа в качестве первых сомножителей умножений; |
| 100 |
ребер, характеризующих некоторые числа в качестве вторых сомножителей умножений; |
| 100 |
ребер, характеризующих числа в качестве результатов умножений. |
Итого, семантическая сеть для представления таблицы умножения содержит 143
вершины и 441 ребро.
Отношения ЭЛ и ПМ задают таксономическую иерархию множеств, используя
которую, можно сократить объем семантической сети. Экономия достигается за счет
того, что общие свойства элементов множества связываются не с каждым отдельным
элементом, а с вершиной, символизирующей типичный элемент множества. Вершина
такого рода является абстракцией, связанной со своим множеством отношением ЭЛ.
При таком подходе доступ к свойствам элемента обеспечивает специальный механизм
наследования [24], анализирующий таксономическую иерархию с целью нахождения
искомого свойства.
Механизм наследования представляет собой один из методов вывода в
семантических сетях. При его реализации возникает проблема множественного
наследования, которая в некотором смысле аналогична проблеме разрешения
конфликтов в продукционных системах. Однако в отличии от продукционных систем,
где задача полностью отдается на откуп интерпретатору, в семантических сетях
предусматриваются специальные средства для отображения приоритетов выбора.
Другой подход к сокращению объема семантических сетей
состоит в использовании так называемого аппарата присоединенных
процедур, которые фактически позволяют сгенерировать необходимый
фрагмент сети непосредственно в ходе вывода.
1.2.3 Фреймы
Теория фреймов разработана М.Минским [45]. Согласно
классическому определению, фрейм есть структура данных для
представления стереотипной ситуации. В инженерии знаний в
качестве стереотипных ситуаций чаще всего выступают
разновидности понятий из проблемной области.
По своему строению фрейм представляет собой двухуровневую
структуру. На верхнем уровне размещается неизменная информация,
характеризующая данный фрейм во всех его проявлениях. На нижнем
уровне находятся так называемые слоты, которые заполняются
конкретными значениями. Слоты устроены достаточно сложно.
Во-первых, слот может содержать специальное значение по
умолчанию, которое действует до тех пор, пока слот не получит
свое настоящее значение. Во-вторых, в качестве значения слот
может содержать ссылку на другой фрейм, раскрывающий содержание
данного слота. Во-третьих, с каждым слотом связывается предикат,
определяющий допустимые границы для его значений. Кроме того,
фрейм может содержать ограничения, которым должны одновременно
удовлетворять значения нескольких слотов.
Фреймы предназначены для узнавания предъявленной ситуации.
Эту операцию обеспечивает так называемый процесс приведения в
соответствие, который пытается сопоставить слотам заданного
фрейма их значения, удовлетворяющие всем ограничениям.
Согласно теории Минского родственные фреймы, по разному
описывающие одно и тоже понятие, связываются в систему фреймов,
использующих общее множество слотов. Система фреймов содержит
зависимости, позволяющие перейти к другому фрейму системы в
случае неуспешного завершения процесса приведения в соответствие.
Наконец, системы фреймов считаются объединенными
специальной сетью извлечения информации, которая выдвигает новую
систему фреймов, если с помощью текущей системы не удалось
опознать предъявленную ситуацию.
Теория фреймов представляет интерес для инженерии знаний в
качестве некоторого подхода к анализу проблемных областей,
нацеливающего когнитолога на выявление слотов, фреймов, их
систем и сети извлечения информации. Вместе с тем, реализация
программных продуктов на базе этой теории возможна только после
уточнения основных понятий. Многочисленные попытки таких
уточнений, в конце концов, выявили общие подходы к реализации фреймов.
Прежде всего необходимо отметить, что инструментальные
средства, поддерживающие представление знаний в виде фреймов,
разрабатываются как специальные языки программирования. По
необходимости, в этих языках главное внимание уделялось
означиванию слотов, в то время как вопросы организации систем
фреймов и сети извлечения информации проработаны слабее.
Рассмотрим основные принципы построения языков для представления фреймов [31].
Каждый фрейм характеризуется уникальным именем и содержит некоторое
количество слотов. Можно считать, что имя символизирует верхние, неизменные
уровни фрейма. Строение слота выглядит значительно сложнее, чем это
предусмотрено в теории Минского.
Во-первых, каждый слот характеризуется уникальным именем,
типом данных и значением. Некоторые слоты предназначаются для
идентификации и систематизации фреймов, их наличие является
обязательным в данном языке. В частности, с помощью специально
оговоренных слотов моделируется таксономическая иерархия фреймов
- аналог таксономической иерархии в семантических сетях.
Во-вторых, для каждого слота пользователь может построить
несколько демонов, отвечающих за перенос информации. Демон
вызывается автоматически при обращении к слоту. Выбор
запускаемого демона определяется формальными событиями процесса
приведения в соответствие. Обычно в языке поддерживаются три типа демонов:
— демон IF_NEEDED, который запускается в момент обращения к
значению слота, если это значение еще не определено;
— демон IF_ADDED, который запускается при первом занесении
значения слота;
— демон IF_REMOVED, который запускается при замене одного
значения слота на другое.
Очевидно, что с помощью демонов IF_NEEDED можно задавать
значения слотов по умолчанию.
В-третьих, с целью управления механизмом наследования
свойств, каждый слот может содержать специальные указатели,
которые задают допустимые для данного слота варианты наследования.
В-четвертых, некоторые слоты (посредством указания
соответствующего типа) можно определить как присоединенные
процедуры, которые запускаются при каждом обращении к слотам.
В языках представления фреймов знания о проблемной области
описываются с помощью фреймов-прототипов, которые не содержат
означенных слотов, но способны в ходе вывода порождать
"заполненные" фреймы-экземпляры. Вывод на фреймах, то есть
процесс приведения в соответствие, и выбор для проверки
очередного фрейма, фактически задается пользователем посредством
присоединенных процедур и демонов.
1.2.4 Логические исчисления
Самым известным способом представления знаний в классе
логических исчислений является логика (предикатов) первого
порядка [49]. В этой формальной теории язык описания формул
строго фиксирован. Алфавит языка образуют символы шести классов:
константы, переменные, функциональные символы, предикатные
символы, логические символы и вспомогательные символы. Правила
конструирования позволяют строить выражения языка - термы и
(правильно построенные) формулы.
Перевод знаний с естественного языка в форму выражений
входит в обязанности когнитолога. Известно, что эта задача
является непростой, она требует определенных навыков и опыта.
Вместе с тем, аналогичная задача стоит перед когнитологом и в
случае построения семантических сетей.
В логике первого порядка рассматриваются строгое
определение логического следствия и связанная с ним задача
проверки: является ли некоторая формула F логическим следствием
формул F1, ..., Fk. Для инженерии знаний
практическая ценность
логики первого порядка связана с существованием алгоритмов,
способных (при некоторых условиях) подтверждать или опровергать
факт наличия логического следствия. Один из методов построения
таких алгоритмов [49] предполагает
— предварительное преобразование формулы
¬F И F1 И ... И Fk в совокупность дизъюнктов и
— последующее применение конечного набора правил преобразований,
важнейшим из которых является так называемое правило резолюции.
Приведем правило резолюции для упрощенной версии логики первого
порядка - логики высказываний:
B1 ИЛИ ... ИЛИ Bi ИЛИ
C1 ИЛИ ... ИЛИ Cj ИЛИ
|
A
ИЛИ ¬A |
ИЛИ Вi+1... ИЛИ Bn
ИЛИ Cj+1... ИЛИ Cm
|
|
B1 ИЛИ ... ИЛИ Bi ИЛИ
C1 ИЛИ ... ИЛИ Cj ИЛИ
|
|
ИЛИ Вi+1... ИЛИ Bn
ИЛИ Cj+1... ИЛИ Cm
|
где A - высказывание;
B1, ..., Bn, С1, ..., Cm - литералы,
то есть либо высказывания, либо отрицания высказываний;
n ≥ 0, m ≥ 0.
В результате применения правила резолюции к паре дизъюнктов, содержащих
соответственно n + 1 и m + 1 литералов, получается дизъюнкт, который называется
резольвентой и который содержит n + m литералов. Резольвента может
использоваться в последующих применениях правила наряду с первоначально
построенными дизъюнктами. Конечная цель таких преобразований состоит в
построении пустого дизъюнкта, не содержащего литералов. Успешное построение
пустого дизъюнкта означает, что формула F является логическим следствием
формул F1, ..., Fk.
Известно, что классическая логика предикатов не пригодна для представления и
обработки противоречивых знаний. В этом смысле она предъявляет повышенные
требования к качеству формализации проблемных областей.
1.2.5 Комбинированные способы представления знаний
Каждая модель знаний допускает определенную свободу при
реализации тех или иных компонент, что открывает возможность
стоить комбинированные способы представления знаний, если того
требуют специфика проблемной области и особенности личных знаний
эксперта. Отметим некоторые направления такого комбинирования.
1. В продукционных системах база фактов может иметь
структуру семантической сети.
2. Присоединенные процедуры в семантических сетях и фреймах могут
реализовываться в виде продукционных систем или с помощью логических
исчислений.
3. Для организации систем фреймов и сетей извлечения информации могут
использоваться продукционные системы или семантические сети.
4. Фреймы могут использоваться в качестве сопоставителей
для анализа базы фактов продукционной системы.
Эти и другие методы комбинирования используют основной
понятийный аппарат моделей знаний. Вместе с тем, любой способ
представления знаний оставляет достаточный простор для выбора
конкретного метода реализации (см., в частности, замечание 1.2).
Речь идет о промежуточных символьных представлениях знаний,
которые будем называть способом реализации баз знаний. (В
качестве примеров сошлемся на так называемые СМ-фреймы [17] и
описательные таблицы [1], предназначенные для реализации
семантических сетей.) Наличие промежуточного уровня в
представлении знаний открывает новые возможности для их
комбинирования. Так, в главе II описан метод реализации баз
знаний, допускающий одновременное представление продукционных
правил и формул логики высказываний.
1.2.6 Модели проблемных областей
Любой программный продукт разрабатывается в интересах решения определенного
круга проблем. Не составляют исключения и системы, основанные на знаниях.
Отличительная особенность этих систем состоит в том, что в них предпринимается
попытка сначала построить формальную модель некоторого фрагмента
действительности, а затем заставить эту модель работать. Естественно,
формальная модель должна быть достаточна для удовлетворительного решения
предварительно намеченного круга проблем. (Именно в этой связи упомянутый
фрагмент действительности называется проблемной областью.)
При всем многообразии способов представления знаний язык
запросов пользователя является достаточно бедным. В своем
запросе пользователь задает описание конкретной проблемной
ситуации. Чаще всего запрос можно рассматривать как
последовательность (конъюнкцию) признаков, характеризующих
проблемную ситуацию. Отметим, что в ответе системы также могут
содержаться признаки, характеризующую проблемную ситуацию.
Единственное отличие состоит в том, что заключения системы
получены путем некоторых вычислений.
Соглашение.
В различных проблемных областях для словосочетания
"признак, характеризующий проблемную ситуацию" существуют
общепризнанные синонимы: "симптом", "свойство" и т.д. Для того,
чтобы избежать нежелательных ассоциаций, введем для обозначения
элементарных характеристик проблемных ситуаций единый термин
"факт".
Каждый факт имеет смысл только тогда, когда с ним связана
некоторая классификация проблемных ситуаций, причем факт
указывает на конкретный подкласс из этой классификации.
Например, факт наличия зеленой окраски неявно предполагает
существование классификации проблемных ситуаций (сущностей) с
точки зрения различных окрасок, причем отдельную группу
составляют сущности зеленого цвета. Классификацию, связанную с
фактом будем называть атрибутом, а ее подклассы - значениями
атрибута. На практике атрибут и его значения представляются
своими именами. Формально факт можно рассматривать как пару
(<Атрибут>,<Значение>). Для структурированных описаний полное
имя атрибута может выглядеть весьма сложно за счет различных
оговорок и уточнений. В стилизованной записи факта имена
атрибута и значения обычно разделяются специальными символами.
Мы будем использовать с этой целью двоеточие.
Замечание.
В принципе, внутреннюю структуру фактов можно не
рассматривать, однако по ряду причин это неудобно, и прежде
всего неудобно для организации интерактивного опроса
пользователя.
В модели проблемной области в качестве атрибутов могут
использоваться числовые показатели, например, РОСТ или ВЕС. В
системах, где ведущая роль принадлежит символическим
преобразованиям, значения таких показателей, в конце концов,
сводятся к агрегированным значениям типа БОЛЬШОЙ, СРЕДНИЙ и т.д.
В связи с этим для инженерии знаний наибольший интерес
представляют атрибуты с конечным числом значений.
В некоторых случаях, в структуре факта разделение на атрибут и значение
основывается не на классификации, а на традиции или строении фраз. Для того,
чтобы отличать такие случаи, будем называть однозначными атрибуты, основанные
на классификации.
Наконец, выделим один подкласс моделей проблемных областей, который явно или
неявно лежит в основе большинства прикладных систем, основанных на знаниях.
Модель проблемной области будем называть признаковой,
| если (1) |
описание проблемной ситуации можно представить в виде последовательности фактов; |
| и (2) |
для построения фактов используются атрибуты с конечным множеством значений. |
1.3 Инструментальные экспертные системы
Вопросы обработки формализованных знаний и, в частности, алгоритмы
логического вывода всегда занимали в искусственном интеллекте центральное
место. Успехи в этом направлении позволили перейти от исследовательских
прототипов к разработке практически полезных программных продуктов - так
называемых экспертных систем. Отметим, что именно массовая разработка
экспертных систем позволила инженерии знаний окончательно оформиться в
самостоятельную дисциплину.
В связи с особенностями знаний, требование практической полезности
отражается в особой организации экспертных систем. Кроме того, во имя получения
практического эффекта, сфера применения отдельно взятой экспертной системы
ограничивается рамками достаточно узкой проблемной области, а также строго
фиксированным классом допустимых запросов пользователя. Приведем архитектуру
типовой экспертной системы, имея ввиду, что в литературе описаны буквально
десятки подобных схем [23], которые отличаются незначительными деталями в
зависимости от целей той или иной публикации.
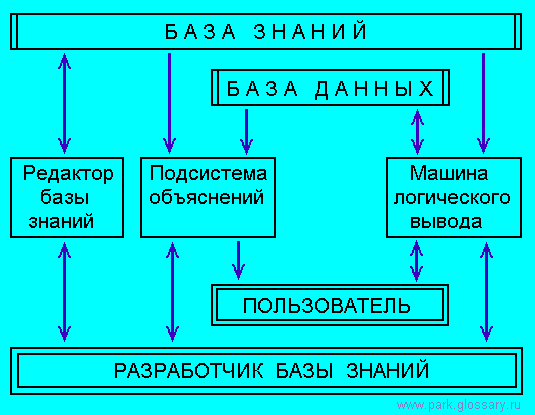
Считается, что пользователем экспертной системы является проблемный
специалист не очень высокой квалификации, способный, по-крайней мере, грамотно
сформулировать свою задачу в виде запроса экспертной системе.
База знаний реализуется по модульному принципу в
соответствии с выбранным способом представления знаний. Кроме
того, база знаний, как правило, содержит некоторые эвристики,
предназначенные для организации работы самой экспертной системы.
Выбор способа представления находится исключительно в
компетенции когнитолога и осуществляется по результатам
выполнения этапа анализа проблемной области. В свою очередь, однажды
зафиксированный способ представления знаний можно рассматривать как
спецификацию на разработку функциональных блоков экспертной системы.
Редактор базы знаний позволяет манипулировать ее содержимым: строить,
модифицировать и удалять знания. Именно редактор позволяет реализовать
технологию прямого извлечения знаний (см. 1.1). Помимо редактора, арсенал
средств формирования баз знаний может включать в себя и другие программные
модули, например, транслятор с языка представления знаний. Обычно редактор
контролирует только синтаксические структуры знаний, хотя известны попытки
построения интеллектуальных редакторов, выполняющих некоторые проверки из
области семантики [27]. Редактор баз знаний является инструментом разработчика
экспертной системы.
Машина логического вывода обслуживает запросы пользователя.
Именно этот функциональный блок экспертной системы позволяет
находить искомые решения на основании содержимого базы знаний. В
своей работе машина вывода использует базу данных, куда
помещаются запросы пользователя и, возможно, результаты
промежуточных выводов. Можно считать, что машина вывода
реализует универсальный алгоритм рассуждения на знаниях [28].
Подсистема объяснений предназначена для того, чтобы
представить пользователю ход рассуждений, приводящих к
полученному результату. Наличие подсистемы объяснений является
определяющим признаком экспертных систем, изменяющих
традиционный взгляд на пользователя программных продуктов. В
новой трактовке он превращается в лицо, принимающее решение о
справедливости или несправедливости полученных результатов. При
этом подсистема объяснений должна помочь пользователю в принятии решения.
Поскольку машина вывода отделена от базы знаний, то в
результате работы экспертной системы могут появиться
незапланированные взаимодействия знаний, приводящие к
неожиданным, но обоснованным решениям. При отладке базы анализ
незапланированных взаимодействий позволяет выявить и устранить
ее недостатки. Если же база знаний абсолютно надежна, то такие
решения представляют интерес не только для пользователя. В связи
с этим существует и развивается отдельная ветвь интеллектуальных
систем, призванных помогать специалистам высокой квалификации.
Под отладкой базы знаний понимается процесс согласования формализованных
знаний в единую систему. При этом ведущую роль играют "потребительские"
качества создаваемой экспертной системы; общение же с самим экспертом играет
роль сугубо утилитарную: от него требуется уточнение и развитие недостаточно
проработанных знаний.
В основе любой реализации средств автоматизированной
отладки лежит некоторая правдоподобная гипотеза о формальных
свойствах правильно построенной базы знаний. Исходя из этой
гипотезы, процедуры отладки позволяют находить в заданной базе
противоречия, упущения и тупики. При обнаружении дефекта
процедура отладки воспроизводит его контекст. Для эксперта
анализ контекста представляет собой разбор некоторой конкретной
проблемной ситуации. В сущности подсистему отладки можно
рассматривать как АСИЗ, ориентированную на прямое извлечение знаний.
По сравнению с другими функциональными блоками подсистема
объяснений является наиболее консервативной компонентой
экспертной системы. В настоящее время известны лишь два подхода
к реализации объяснений [60]. Первый подход предполагает
использование в качестве объяснения формальных
причинно-следственных связей, построенных машиной вывода. Второй
подход основывается на том, что по ходу логического вывода
пользователю предъявляются в определенном порядке заранее
подготовленные сообщения, которые хранятся в базе знаний. Для
разработчика экспертной системы машина вывода и подсистема
объяснений являются инструментами тестирования баз знаний.
Учитывая это обстоятельство, первый подход к реализации
подсистем объяснений имеет определенные преимущества, поскольку
он полностью определяется способом представления знаний.
Специально для разработки экспертных систем предназначены
два класса инструментальных средств: пустые экспертные системы и
системы-оболочки [48]. Пустая экспертная система предоставляет в
распоряжение когнитолога фиксированный способ представления
знаний и ориентированные на него функциональные блоки. По сути
дела, пустая экспертная система навязывает когнитологу решение
ряда принципиальных вопросов, оставляя на его усмотрение лишь
технологию заполнения базы знаний. Система-оболочка позволяет
когнитологу определить способ представления знаний, а затем
построить ориентированные на него функциональные блоки
экспертной системы. Формально система-оболочка реализует более
гибкий подход к построению экспертных систем. Вместе с тем,
удачный выбор пустой экспертной системы может оказать неоценимую
помощь при построении рабочего прототипа будущей экспертной системы.
1.4 Принципы организации опроса эксперта и системы приобретения знаний
Продуктивность опроса эксперта во многом определяется
поведением когнитолога. При отсутствии универсальных рецептов в
инженерии знаний тем не менее накоплено некоторое количество
рекомендаций по "правильной" организации диалога.
(1) В интересах дела когнитолог должен поддерживать
заинтересованность эксперта в результатах работы. С этой целью
можно использовать познавательный интерес эксперта к пониманию
природы собственного мастерства. Отвечая на это стремление,
когнитолог должен время от времени демонстрировать эксперту
нетривиальные фрагменты его знаний. Другой подход состоит в том,
что когнитолог может поддерживать интерес посредством включения
в диалог элементов игры, рассчитывая пробудить у эксперта
обыкновенное любопытство и даже азарт.
(2) Для того, чтобы избавить эксперта от рутинной работы
когнитолог должен с максимальной отдачей использовать
альтернативные источники знаний: специальную литературу,
эмпирические данные и т.д. При этом необходимо учитывать, что не
все полученные знания устроят эксперта. Например, процедуры
индуктивного вывода, как правило, находят несколько
конкурирующих вариантов закономерностей, и только эксперт имеет
право принимать или опровергать тот или иной вариант. Работа по
оценке закономерностей сродни прямому извлечению знаний,
поскольку эксперту приходится иметь дело непосредственно с
формальными структурами знаний. Однако в этом случае он избавлен
от обременительной обязанности "писать с чистого листа".
Аналогичная ситуация имеет место и при отладке, когда эксперта
приходится привлекать к анализу дефекта, выявленного в базе знаний.
Подчеркнем, что применение этих и других рекомендаций требует неформального
отношения к делу. Вместе с тем, накопленный опыт дает ориентиры для разработки
АСИЗ.
Перейдем к систематическому изложению методов опроса эксперта [8,32], при
этом будем обращать особое внимание на системы приобретения знаний,
поддерживающие соответствующие методы опроса.
1.4.1 Простое и структурированное интервью
Простое интервью применяется на начальных этапах извлечения
знаний. При этом цель когнитолога состоит в том, чтобы выявить
структуру решаемых задач, наметить проблемную область и
выполнить (если это возможно) ее декомпозицию. Особое внимание
когнитолог должен уделить выявлению решений, для нахождения
которых и предпринимается попытка построить программную систему.
Особенности множества решений во многом определяют содержание
последующих этапов: либо когнитолог попадает в исследованные
случаи "хороших" решений, либо ему предстоит идти своим,
неизведанным путем. К "хорошим" решениям, например, относятся:
список неисправностей, каталог изделий, систематизация
микроорганизмов. Общей чертой "хороших" решений является простота их имен в
сочетании с возможностью полного перечисления всех решений.
Простое интервью не навязывает какого-то определенного
стиля общения, однако когнитологу рекомендуется придерживаться
роли человека, интересующегося проблемой. Для того, чтобы
направлять ход беседы, когнитолог должен предварительно
подготовить небольшой список основных вопросов. Простое интервью
предполагает, что ответы эксперта должны быть краткими,
свободными от деталей. По результатам проведенного интервью
когнитолог составляет словарь специальных терминов, список
ключевых задач и вариантов их решения.
Структурированное интервью применяется для детального
анализа проблемной области. По форме структурное интервью
строится в виде вопросов и ответов. Причем вопросы когнитолога
должны быть совершенно конкретными, а ответы эксперта -
обстоятельными. В ходе подготовки к сеансу когнитолог составляет
список тем, подлежащих обсуждению. При этом существенно
используются результаты простого интервьюирования.
В начале сеанса рекомендуется ознакомить эксперта с
намеченными темами с тем, чтобы он мог изменить порядок их
рассмотрения. Обсуждение каждой темы следует начинать с общего
обзора, который полезно повторить по ее завершении. Каждый сеанс
извлечения знаний продолжается до тех пор, пока когнитолог
способен понимать эксперта. При возникновении у когнитолога
серьезных затруднений сеанс рекомендуется прервать. По
результатам структурированного интервью когнитолог выявляет
объекты и понятия проблемной области, а также связывающие их отношения.
Преследуя свои цели, когнитолог должен исподволь направлять
ход беседы в нужное ему русло. Для этого он должен свободно
владеть специальными приемами зондирования:
— (пополняющее зондирование) если эксперт впервые затронул
некоторую тему, и когнитолог заинтересован в получении любой
информации по этой теме, то репликами типа "Продолжайте дальше",
когнитолог стимулирует эксперта развивать свою мысль;
— (директивное зондирование) если когнитолог заинтересован в
том, чтобы переключить обсуждение на другую тему, то он может
сделать это с помощью вопроса типа "А что будет в этом случае?";
— (определяющее зондирование) если когнитолог не понимает
отдельные понятия или термины, то объяснения эксперта можно
прервать и обратиться к нему за разъяснениями; таким образом
когнитолог может ликвидировать возникшее у него непонимание и
тем самым "спасти" сеанс извлечения знаний;
— (зондирование с изменением образа действия) если эксперт
испытывает затруднения в обсуждении некоторой темы, то
когнитолог может предложить ему изменить подход к обсуждению;
например, когнитолог может обратиться к эксперту с просьбой
рассмотреть методологический или функциональный аспект данной темы.
Время от времени когнитолог должен устраивать ревизию
(критический обзор [32]) собранных материалов, привлекая к
этой работе эксперта. Прежде чем приступить к обсуждению
текущего состояния дел, когнитолог должен систематизировать
собранные термины, факты и отношения. В ходе обсуждения
представленных материалов задача эксперта состоит в том, чтобы
оценить полноту охвата проблемной области. По результатам такой
ревизии зачастую ликвидируются пробелы в давно, казалось бы, закрытых темах.
Общение с экспертом в стиле простого и структурированного
интервью практически не поддается автоматизации, а для
облегчения рутинной работы когнитолога разрабатываются
специальные методологии и программные средства их поддержки.
Типичная методология [57] базируется на некотором наборе понятий
метауровня, которые конкретизируются в ходе извлечения знаний.
Несколько иной подход к автоматизации рутинной работы
когнитолога реализуют специализированные гипертекстовые
оболочки. Некоторые из них также фиксируют набор метапонятий в
виде типов узлов и связей гипертекста [54], другие позволяют
проводить такую типизацию самому когнитологу [59].
1.4.2 Протокольный анализ
Протокольный анализ предполагает, что эксперт комментирует свои действия
по ходу решения задачи. Полученный подобным образом протокол "мыслей вслух"
несет определенную информацию о механизмах вывода решений.
Соглашение.
В последующем изложении будем различать описания проблемных
ситуаций и примеры решения задач. Пример представляет собой
описание проблемной ситуации с заранее известными решениями.
Существуют несколько вариантов протокольного анализа -
моделирование сценария, самоотчет и метод наблюдения. Во всех
случаях протокольный анализ позволяет когнитологу сформировать, по-крайней
мере, набор контрольных примеров практического применения знаний.
При моделировании сценария эксперт адресует свои реплики когнитологу,
объясняя содержание задачи и способ ее решения. Несмотря на все недостатки
такого объяснения (см. 1.1), полученная информация позволяет когнитологу
сформировать рабочую гипотезу о механизмах вывода решений.
При самоотчете эксперт адресует реплики самому себе. В этом
случае протокол не содержит объяснений, а потому в большей
степени соответствует истинному ходу рассуждений. Протокол
самоотчета можно использовать для уточнения рабочей гипотезы, а
также для выявления прагматики знаний, полученных, скажем, в
результате интервьюирования.
Метод наблюдения можно рассматривать как вырожденный случай
самоотчета, когда эксперт не выполняет никакого дополнительного
задания, а просто решает задачу в естественной обстановке. При
этом от эксперта поступает минимум информации, и когнитологу,
пассивно фиксирующему последовательность событий, приходится в
основном рассчитывать на свои догадки и интуицию.
Инструментальные средства расшифровки протоколов исходят из
некоторых общих представлений о их строении. Так, в системе
KRITON [56] считается, что текст протокола можно разделить на
смысловые сегменты, соответствующие этапам вывода решения.
Разбиение на сегменты осуществляется на основании пауз между
фразами. В свою очередь анализ сегментов предполагает, что
когнитолог должен выделить в их структуре операторы и аргументы.
Следующие три группы методов опроса предполагают, что эксперт проявляет свое
профессиональное мастерство в ситуациях искусственно созданных
когнитологом [5].
1.4.3 Метод декомпозиции цели
Метод декомпозиции цели состоит в том, что когнитолог
предъявляет эксперту некоторое решение и предлагает сообщить
условия его достижимости. Если эксперт способен выполнить это
задание, то в результате будет выявлена структура основных
подзадач и условий их появления. Однако этот метод опроса может
не сработать, когда в проблемной области имеется большое
количество вариантов достижения одних и тех же решений.
Очевидно, что метод декомпозиции цели аналогичен стратегии
обратного вывода в продукционных системах.
1.4.4 Методы сопоставления
Методы сопоставления предназначены для построения
таксономической иерархии проблемной области. Основной прием
опроса состоит в том, что когнитолог предъявляет эксперту
несколько решений и предлагает рассмотреть некоторый конкретный
вопрос об их сходстве и/или различии. Для удобства каждое
решение может быть записано на отдельной карточке, что позволяет
эксперту вполне предметно объединять сходные и разделять
контрастные решения. Если от эксперта требуется лишь
сгруппировать решения, то его ответ интерпретируется как наличие
некоторых классов решений, имеющих общие родовые черты. Названия
классов могут использоваться в качестве решений в последующих
вопросах когнитолога. Если от эксперта требуется объяснить свои
действия, то в результате будет выявлен некоторый атрибут. Таким
образом, сопоставление решений используется как методологический
прием, стимулирующий эксперта излагать свои знания.
Относительная простота и "прозрачность" методов
сопоставления буквально спровоцировала появление целого
семейства систем извлечения знаний, непосредственно
ориентированных на диалог с экспертом. Все эти системы
предполагают, что исходное множество решений выявлено заранее и
его достаточно просто ввести в базу знаний. Основной вопрос, с
которым система обращается к эксперту, содержит тройку некоторых
решений и задание сопоставить их (разбить на две группы) в
соответствии с методикой репертуарных решеток (см. 5.1).
Приведем наиболее значительные и известные системы этого семейства (в скобках
указаны особенности реализации метода репертуарных решеток):
— система KRINON [56] (в том случае, когда эксперт затрудняется
с разбиением тройки, система переходит к опросу о структуре классов);
— система AQUINAS [53] (позволяет сформулировать полученные знания в
виде продукционных правил, которые предъявляются эксперту для оценки);
— система KITTEN [61] (позволяет сформулировать правила с
коэффициентами уверенности);
— система SIMER [25] (использует методы сопоставления для
уточнения типа бинарного отношения, связывающего заданные решения);
— система ЭСКИЗ [1] (реализует стратегию перехода к
сопоставлению пар решений).
1.4.5 Методы заочной консультации
Идея заочной консультации как метода извлечения знаний
состоит в том, что когнитолог предлагает эксперту решить некоторую
задачу по заданному (формальному) описанию проблемной ситуации.
Заочная консультация допускает различные варианты опроса.
Самый простой из них состоит в том, что когнитолог полностью
предъявляет описание ситуации и ведет протокол рассуждений
эксперта. Другой вариант предусматривает последовательное
предъявление фрагментов описания по запросам эксперта.
Последний вариант заочной консультации детально проработан
в методологии диагностических игр [6]. С самого начала
диагностические игры разрабатывались и использовались как
методика работы когнитолога, без ориентации на программную
реализацию. Закономерным итогом такого подхода явился набор
рекомендаций по поиску и подготовке описаний, правилам поведения
когнитолога и т.д. Характерно, что в ходе опроса когнитолог
должен проявлять полную бесстрастность с тем, чтобы не дать
эксперту невольную подсказку.
Различные варианты опроса методом заочной консультации реализуются в классе
экспертных игр (см. главу VI). Отметим, что экспертные игры существенно
ориентированы на использование осмысленных примеров решения задач.
Особого разговора заслуживает формальное построение
описаний. Формальный подход имеет смысл только в том случае,
когда язык описания ситуаций строго фиксирован. Например, это
может быть признаковая модель проблемной области. Если бы в ходе
заочной консультации эксперт смог рассмотреть и вынести решение
по каждому описанию, то проблема построения баз знаний
упростилась бы радикально. В связи с тем, что количество
формальных описаний превосходит все разумные пределы, этот
подход к извлечению знаний долгое время считался
бесперспективным. Однако разработанный в системе МЕДИКС [16]
метод доминирования позволяет по-новому взглянуть на перебор
описаний. Процедура извлечения знаний, реализованная в системе
МЕДИКС, состоит из двух этапов.
На первом этапе эксперту предлагается проанализировать все
пары решений и атрибутов. Цель единичного акта анализа состоит в
том, чтобы для заданного решения линейно упорядочить значения
атрибута, начиная с самого типичного. По результатам выполнения
этапа для каждого решения строится отношение частичного порядка
на описаниях, которое называется отношением доминирования.
Переход от порядка на значениях к порядку на описаниях является
основной посылкой метода. В результате такого перехода система
получает возможность сравнивать некоторые пары описаний на
"большую" или "меньшую" типичность относительно заданного решения.
Второй этап извлечения знаний в системе МЕДИКС организован
в стиле заочной консультации. Эксперту предъявляются описания
ситуаций и предлагается выносить решения. Одновременно с
решением система получает и отношение доминирования, что
позволяет автоматически распространить ответ эксперта на все
"более типичные" описания. При удачном стечении обстоятельств
таким образом удается исключить из рассмотрения сразу несколько описаний.
Понятно, что успех метода доминирования определяется тем,
насколько контрастными окажутся шкалы, выявленные на первом
этапе. В худшем случае на втором этапе метод вырождается в
полный перебор описаний. Вместе с тем, даже при благоприятном
стечении обстоятельств метод применим для признаковых моделей с
относительно небольшим числом однозначных атрибутов (до 12-14).
Учитывая специфику личных знаний эксперта (п. 1.1), а также исходя
из анализа приемов опроса эксперта, уточним общие требования к АСИЗ.
1. Автоматизированная система инженерии знаний должна
ставить перед экспертом только такие вопросы, на которые он
способен дать ответ. В настоящее время известны всего два
базовых подхода к организации интерфейса извлечения знаний в
АСИЗ: методы сопоставления и методы заочной консультации.
2. Автоматизированная система инженерии знаний должна предоставлять
когнитологу средства оценки собственной применимости. Поскольку применение
систем извлечения знаний связано с определенным риском их неприятия со стороны
эксперта, то когнитолог должен располагать методикой, позволяющей определить
степень применимости системы в конкретных обстоятельствах. Неприятие может
проявляться в разных формах: от категорического отказа до отказа следовать
отдельным правилам. В некоторых случаях опасность представляет изменение
мотивов поведения эксперта. В конечном итоге вопрос применимости метода
- это вопрос о достоверности извлекаемых знаний.
3. Система извлечения знаний должна вести полный протокол опроса эксперта.
1.5 Принципы построения автоматизированных систем инженерии знаний
В структуре любой АСИЗ независимо от ее конкретной реализации существуют три
компоненты: блок настройки, интерфейс извлечения знаний и блок анализа
протоколов.
1. Блок настройки позволяет подготовить АСИЗ к работе в
конкретной проблемной области. Настройка, как правило,
осуществляется когнитологом на основании предварительного
исследования проблемной области (п. 1.4.1) и последующего выбора
модели проблемной области (п. 1.2.6).
Непосредственным результатом настройки является база
сведений о проблемной области. В зависимости от специфики АСИЗ в
качестве сведений могут, например, использоваться формальные
структуры знаний или данные о решениях, примерах и т.д.
Содержимое базы может изменяться и модифицироваться по ходу
использования АСИЗ для построения базы знаний.
2. Интерфейс извлечения знаний ориентирован на
интерактивное взаимодействие с экспертом. Этот программный блок:
- реализует сценарий опроса эксперта - сценарий извлечения знаний;
- использует в своей работе базу сведений о проблемной области;
- протоколирует все действия эксперта, формируя базу протоколов опроса.
Сценарий извлечения знаний должен одновременно удовлетворять двум
условиям продуктивности.
Условие 1.1
Сценарий опроса должен учитывать особенности личных знаний эксперта
(п. 1.1) с тем, чтобы стимулировать эксперта проявлять нетривиальные знания.
Условие 1.2
Протоколы опроса должны допускать интерпретацию в терминах
того или иного формального способа представления знаний (п. 1.2).
Вне зависимости от конкретной реализации все сценарии опроса имеют
циклическую организацию: во времени опрос эксперта развивается в виде
последовательности туров, каждый из которых проводится по одни и тем же
правилам, но с разными исходными данными. В связи с этим каждый сценарий
неизбежно реализует тот или иной алгоритм выбора сведений для проведения
очередного тура. Этот алгоритм будем называть управляющей стратегией
сценария извлечения знаний.
3. Блок анализа протоколов реализует инструментальную
поддержку деятельности когнитолога. Этот программный блок
обеспечивает решение трех основных задач:
- оценку применимости соответствующего сценария опроса для
конкретного эксперта;
- выделение продуктивной части протокола;
- преобразование выделенной части протокола в формальные
структуры знаний.
Окончательное решение по этим задачам принимает когнитолог, а
блок анализа протоколов должен предоставить для этого соответствующую
информацию и предложить на выбор возможные варианты решений.
В некоторых случаях для оценки применимости и выделения
продуктивной части протокола используются математические методы.
Преобразование протокола (или его выделенной части) в формальные
структуры знаний всегда носит эвристический характер, в этой
части АСИЗ можно говорить только о той или иной степени
правдоподобности методов построения формальных структур знаний.
Схема информационных потоков в типовой АСИЗ представлена на
следующем рисунке:
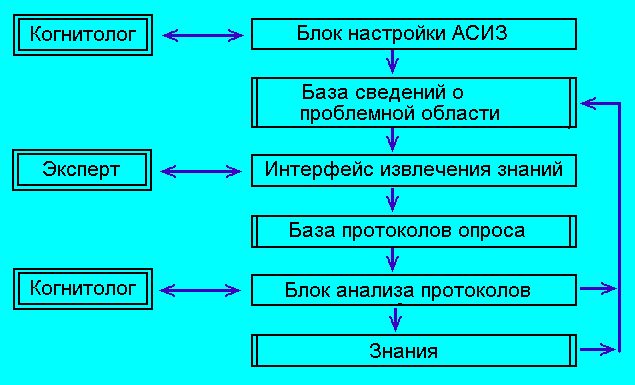
С функциональной точки зрения использование АСИЗ предполагает попеременную
работу с соответствующими блоками эксперта и когнитолога.Завершая общий анализ автоматизированных систем инженерии знаний, отметим,
что любая концепция того или иного класса программных продуктов, имеет право
на существование только в том случае, когда допускает реализацию нетривиальных
и практически полезных программ.
1.6 Специальные обозначения
В интересах описания математических методов АСИЗ приведем систему
базовых понятий, использующихся во всем последующем изложении.
1. Если A - некоторое множество, то запись n = ||A||
означает, что множество A конечно и содержит n элементов.
2. Если A - некоторое множество, то запись 2A означает
множество всех его подмножеств.
3. Разбиением множества A называется совокупность его попарно
непересекающихся подмножеств B (B ⊂ 2A \ {∅})
таких, что
4. Если R - некоторое бинарное отношение на множестве A, то будем обозначать:
R+ - транзитивное замыкание отношения R;
R* - рефлексивное и транзитивное замыкание отношения R.
5. Ориентированным графом называется пара <M,W>,
где M - множество вершин, W - множество ребер.
Как правило, ребра будут задаваться упорядоченными парами вершин.
Последовательность элементов из W вида
(m0,m1) (m1,m2)...(mk-1,mk)
называется путем [m0,mk] из вершины m0 в вершину mk.
При этом будем говорить, что
(а) вершина mk достижима из вершины m0;
(б) путь проходит через вершины m0, ..., mk,
из которых m1, ..., mk-1 являются внутренними.
6. Деревом называется ориентированный граф c выделенной вершиной r
(называемой корнем), у которого:
(а) полустепень захода вершины r равна 0;
(б) полустепень захода всех остальных вершин равна 1;
(в) каждая вершина достижима из корня.
Всем вершинам дерева однозначно приписываются значения глубины:
(а) глубина(r) = 0;
(б) если две вершины дерева соединены ребром (m1,m2),
то глубина(m2) = глубина(m1) + 1.
Узел дерева для ребер (m,m1), ... (m,mn),
исходящих из вершины m, будем изображать на рисунках в виде
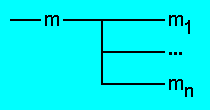
В некоторых случаях на местах вершин m,
m1, ..., mn будут помещаться их метки.
|